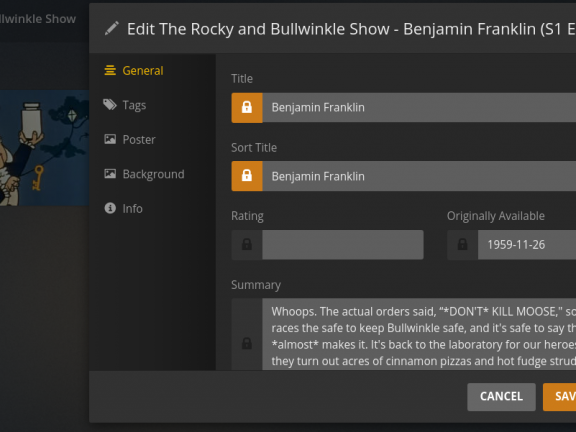
bullwinkle’s how to title titles, or, sqlite in plex for fun and panic
I’ve been going through my entire cartoon library and re-encoding stuff because I’ve done a lot of QA on what looks best for encodes (more on that in another blog… Read more »
cartoons, dragons, linux, multimedia, psychology, skateboarding, movies, mentoring, programming, and more
I’ve been going through my entire cartoon library and re-encoding stuff because I’ve done a lot of QA on what looks best for encodes (more on that in another blog… Read more »
Today’s adventure in coding was to continue to moving Blu-ray support into my DVD ripper software. The next step was getting the priority audio codecs that I wanted when remuxing… Read more »
Okay, so here’s a question I would normally pose to a mailing list, but since my email setups are so jacked up at the moment, there really isn’t a good… Read more »
I just found a workaround to something I’ve always preferred to do in SQL. I’m using MySQL 5 at work, and I had a query where I would order the… Read more »
I’ve been job hunting, and while my dream job would be somewhere that uses PostgreSQL, I am having an extremely hard time finding anyone that uses it. So, I think… Read more »
I’m still working on cleaning up the import scripts for GPNL, and I’m going to have to start using PHP’s PDO database layer to connect to an SQLite3 database at… Read more »
I was googling for a postgresql image I could use when I found this page, a nice short summary on the differences between MySQL and PostgreSQL with an emphasis on… Read more »
Well, that was fast. I looked at the schema last night for the MDP Scriptures project, and started cleaning it up, and it went really quickly. I’ve got a postgres… Read more »
I mentioned not too long ago that I was working on getting portage details crammed into postgresql, and here is the end result. GPNL is meant to be a QA… Read more »
I have not worked on my LDS Scriptures project in a very long time. In fact, annual realeases are becoming an embarrassing reality. However, I’ve been itching to update the… Read more »