I’ve been going through my entire cartoon library and re-encoding stuff because I’ve done a lot of QA on what looks best for encodes (more on that in another blog post). I was working on Rocky & Bullwinkle, and ran into a problem with TVDB (the source that Plex uses to get metadata about a show). Although one show will run five different segments, the series listing for the cartoon only does the first and fifth segment per show, stripping out the rest.
A picture will probably describe the original layout better:
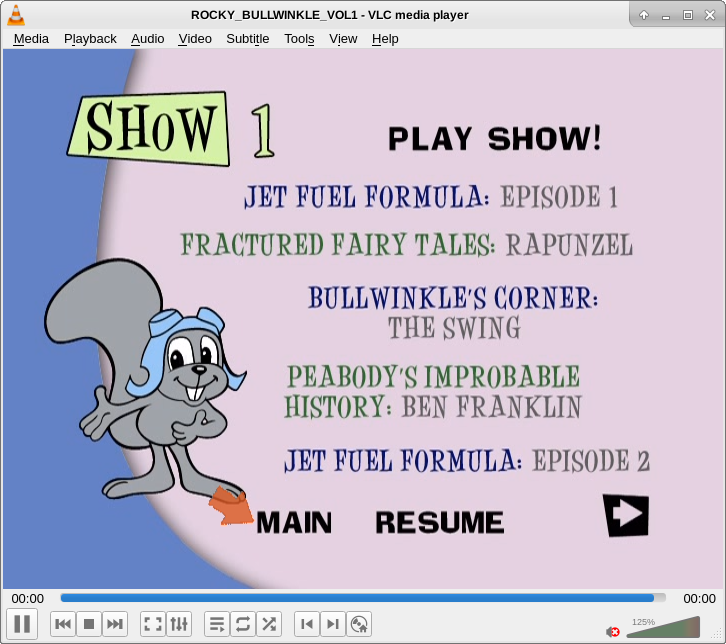
Sources like these are tricky to deal with. The actual show itself, in its half-hour program, was five segments, but the sequence “Jet Fuel Formula” actually ran for 40 episodes across multiple programs and DVDs! The TVDB handles situations like this differently, but not always in the same method. They decided to split the show a couple of different ways. For example, “Fractured Fairy Tales,” has its own series. “Peabody’s Improbable History” shows up later in Rocky and Bullwinkle’s. There are other series where the same thing crops up – more than one “series” is in a show — Huckleberry Hound and Snagglepuss are split into two series, even though are on the same DVD set. Anomalies like this are difficult to work with, which is not completely unusual when it comes to source material that is split up like this, and TVDB shouldn’t be criticized in any way, there are a lot of complex situations and the contributors do a masterful job of dealing with it.
However, I want to replace what Plex is displaying as the title names with what I’ve actually ripped. No problem, that’s why we hack on things.
Plex will let you set a custom title for a show, along with any other metadata you’d like to change. I could do it manually, but I keep track of everything in my own application in separate database (PostgreSQL if you’re curious) along with all the information about my DVD library, and so I can automate everything.
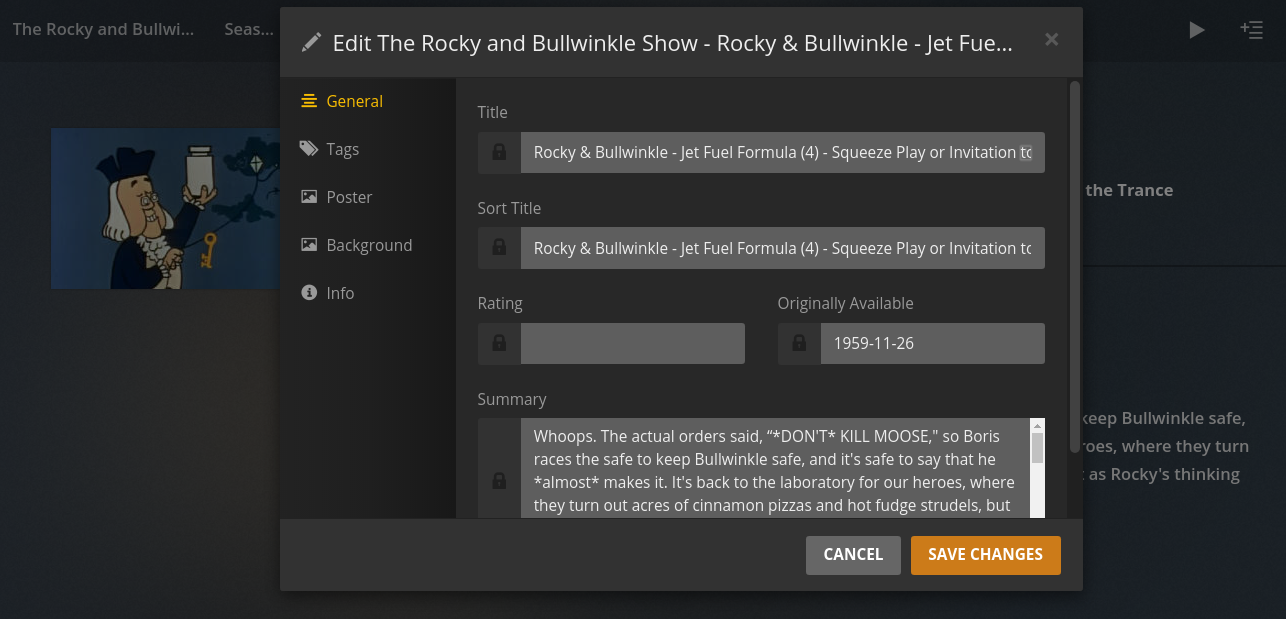
When the metadata is changed and saved manually, there will be an orange background color behind the lock for the specific item. That’s my goal. I just need to poke at the Plex database directly.
Plex very wisely uses SQLite for its backend database. I can only imagine the horror of running a database with a daemon in the background, it would just introduce a new litany of issues that would have to be debugged.
On my Linux box, the Plex database is at ‘/var/lib/plexmediaserver/Library/Application Support/Plex Media Server/Plug-in Support/Databases/com.plexapp.plugins.library.db’. I should add that it’s really important that you back up your database before doing anything. Here’s a very simplified example:
$ sqlite3 '/var/lib/plexmediaserver/Library/Application Support/Plex Media Server/Plug-in Support/Databases/com.plexapp.plugins.library.db' .dump > plex.sqlite.db
If you want to play things safe (you probably do) you could stop the Plex daemon if you wanted to before making any changes to the database. It’s fine if you don’t, though. Any writes to the database will be blocked if there’s an active lock on it from another process (Plex), so you’d just have to rerun it.
I had to browse through the schema a bit (which from what I can tell, is efficiently developed as well) so I could figure out the relations between everything. But first I wanted to see what table the file was actually in. So, here’s the first thing I ran, was to dump the database contents and grep to see which one it stores filenames in:
$ sqlite3 plex.sqlite.db .dump | grep '/home/steve/media/libraries/cartoons/The Rocky and Bullwinkle Show (1959)/Season 01/The Rocky and Bullwinkle Show - s01e04.mkv'
Which returned:
INSERT INTO media_parts VALUES(63656,62837,10968,'16c528645206d1cbfbb58ed03365ff00eb538b2c','7e6f54f50fb00a7d','/home/steve/media/libraries/cartoons/The Rocky and Bullwinkle Show (1959)/Season 01/The Rocky and Bullwinkle Show - s01e04.mkv',NULL,187207847,348551,'2020-04-22 14:00:10','2020-04-22 04:14:52',NULL,'ma%3Acontainer=mkv&ma%3AvideoProfile=high&mi%3Aindexes=sd');
That first integer (63656) is surely a unique identifier, and those next two columns (62837, 10968) are reasonably a foreign key. Dump the schema and look at that (note that I’m going the long way here, I originally did this with DB Browser for SQLite, but I’m too lazy right now and I want to see if I can find it through command line only).
Get the schema for that table (I’m using a symlink here for the DB):
$ sqlite3 plex.sqlite.db .schema | grep media_parts | head -n 1
Which returns:
CREATE TABLE IF NOT EXISTS "media_parts" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "media_item_id" integer, "directory_id" integer, "hash" varchar(255), "open_subtitle_hash" varchar(255), "file" varchar(255), "index" integer, "size" integer(8), "duration" integer, "created_at" datetime, "updated_at" datetime, "deleted_at" datetime, "extra_data" varchar(255));
Okay, so media_item_id is definitely what I’m looking for here. Get the schema of that as well:
$ sqlite3 plex.sqlite.db .schema | grep media_items | head -n 1
And get its output:
CREATE TABLE IF NOT EXISTS "media_items" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "library_section_id" integer, "section_location_id" integer, "metadata_item_id" integer, "type_id" integer, "width" integer, "height" integer, "size" integer(8), "duration" integer, "bitrate" integer, "container" varchar(255), "video_codec" varchar(255), "audio_codec" varchar(255), "display_aspect_ratio" float, "frames_per_second" float, "audio_channels" integer, "interlaced" boolean, "source" varchar(255), "hints" varchar(255), "display_offset" integer, "settings" varchar(255), "created_at" datetime, "updated_at" datetime, "optimized_for_streaming" boolean, "deleted_at" datetime, "media_analysis_version" integer DEFAULT 0, "sample_aspect_ratio" float, "extra_data" varchar(255), "proxy_type" integer, 'channel_id' integer, 'begins_at' datetime, 'ends_at' datetime
I’ll save time now and skip ahead because I’m getting tired. The next relative column here now is ‘metadata_item_id’.
Get the schema of that, and it very much looks like where things about things are stored:
$ sqlite3 plex.sqlite.db .schema | grep metadata_items | head -n 1
Which gives us this next on that table:
CREATE TABLE IF NOT EXISTS "metadata_items" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "library_section_id" integer, "parent_id" integer, "metadata_type" integer, "guid" varchar(255), "media_item_count" integer, "title" varchar(255), "title_sort" varchar(255) COLLATE NOCASE, "original_title" varchar(255), "studio" varchar(255), "rating" float, "rating_count" integer, "tagline" varchar(255), "summary" text, "trivia" text, "quotes" text, "content_rating" varchar(255), "content_rating_age" integer, "index" integer, "absolute_index" integer, "duration" integer, "user_thumb_url" varchar(255), "user_art_url" varchar(255), "user_banner_url" varchar(255), "user_music_url" varchar(255), "user_fields" varchar(255), "tags_genre" varchar(255), "tags_collection" varchar(255), "tags_director" varchar(255), "tags_writer" varchar(255), "tags_star" varchar(255), "originally_available_at" datetime, "available_at" datetime, "expires_at" datetime, "refreshed_at" datetime, "year" integer, "added_at" datetime, "created_at" datetime, "updated_at" datetime, "deleted_at" datetime, "tags_country" varchar(255), "extra_data" varchar(255), "hash" varchar(255), "audience_rating" float, "changed_at" integer(8) DEFAULT 0, "resources_changed_at" integer(8) DEFAULT 0);
Now you can see column names that look like they would match in the web interface: “title,” “title_sort,” “summary,” and so on. So this where the changes need to go.
So to join it all together right now, and see some of the metadata, just the title for now, let’s run the query joining everything together:
SELECT metadata_items.id, metadata_items.title, metadata_items.title_sort FROM metadata_items JOIN media_items ON media_items.metadata_item_id = metadata_items.id JOIN media_parts ON media_parts.media_item_id = media_items.id WHERE media_parts.file = '/home/steve/media/libraries/cartoons/The Rocky and Bullwinkle Show (1959)/Season 01/The Rocky and Bullwinkle Show - s01e04.mkv';
From the results, I can see what’s set by TVDB (also, I enabled headers in my SQLite session, .headers on):
id|title|title_sort
73162|Rocky & Bullwinkle - Jet Fuel Formula (4) - Squeeze Play or Invitation to the Trance|Rocky & Bullwinkle - Jet Fuel Formula (4) - Squeeze Play or Invitation to the Trance
Now that I know the metadata_items.id I can update the table. There’s two things remaining though: I need to let Plex know that this is a manual override, and also that the content has changed. If I toggle with the locks back in the edit page on the website, and see what’s changed in the database, two column entries have been modified, ‘user_fields’ and ‘changed_at’. (Also, I got tired of digging manually and went back to DB Browser again, and by tired, I mean stuck)
The ‘user_fields’ table uses a syntax of ‘locked_fields=INDEX|INDEX’ where INDEX is a one-based integer relative to the fields start (1 = Title, 2 = Sorted Title, etc.). ‘changed_at’ just got incremented by 1.
So now, the final query, to update Plex, get my title in there:
UPDATE metadata_items SET title = 'Benjamin Franklin', title_sort = 'Benjamin Franklin', user_fields = 'lockedFields=1|2', changed_at = changed_at + 1 WHERE id = 73162;
And that gives me this when I go back to Plex:

And there you go. That should be enough to get someone started if they want to manually make changes to their Plex database.
I’d recommend making a view of joining all the tables so it’s easier to look stuff up. For example:
CREATE VIEW view_filename_meta AS SELECT metadata_items.*, media_parts.file AS media_parts_file FROM metadata_items JOIN media_items ON media_items.metadata_item_id = metadata_items.id JOIN media_parts ON media_parts.media_item_id = media_items.id;
Then just run a query against that with the filename:
SELECT * FROM view_filename_meta WHERE media_parts_file = '/home/steve/media/libraries/cartoons/The Rocky and Bullwinkle Show (1959)/Season 01/The Rocky and Bullwinkle Show - s01e04.mkv';
73160|15|73159|4|com.plexapp.agents.thetvdb://76705/1/2?lang=en|1|Custom Title|Custom Sort|||||||||||2|||metadata://seasons/1/episodes/2/thumbs/com.plexapp.agents.thetvdb_64d369e9cecfc3371ec9f87cd43d4d47c11626ca||||lockedFields=1|2||||||1959-11-19 00:00:00|||2020-04-22 18:46:38|1959|2020-04-22 16:08:41|2020-04-22 14:00:10|2020-04-22 16:09:03|||ma%3AchapterSource=|6b7d2440b29c8c5cdccf0ffe5fc1308e1e6c3245||2899425|2899041|/home/steve/media/libraries/cartoons/The Rocky and Bullwinkle Show (1959)/Season 01/The Rocky and Bullwinkle Show - s01e04.mkv
And you’re done! The metadata_item.id is right there (73160) and you know what to update.
UPDATE metadata_items SET title = 'Benjamin Franklin', title_sort = 'Benjamin Franklin', user_fields = 'lockedFields=1|2', changed_at = changed_at + 1 WHERE id = 73160;
Have fun, and go watch some cartoons!

Maybe Plex changed but all you have to do if you want to see all embedded epsiodes in a show file is use an episode range. e.g. s01e01-e05 flex knows what to do and digs out all 5 episodes (chapters really) from the show file and displays them as 5 separate episodes correctly numbered. What I want to do is display every thing by show not by individual episodes. The only way I can figure out is to number the show file by 5’s of course I only see the description of the first episode on the file unless I edit it. That’s a lot to edit. Someone started a show level listing in tvdb (but only the first season has descriptions of what’s in the show) and I can;t figure out how to use that instead anyway.